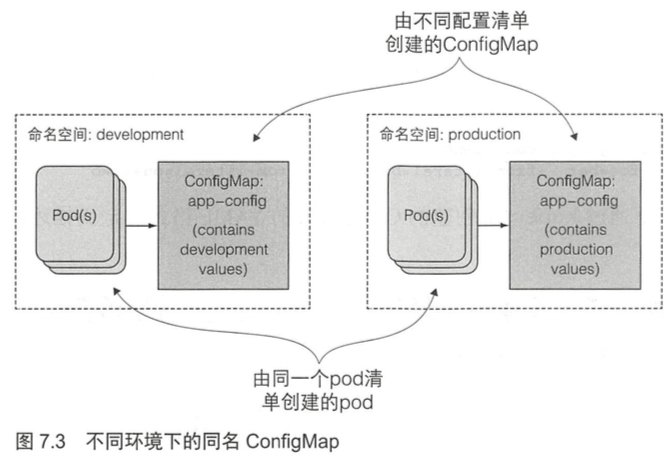
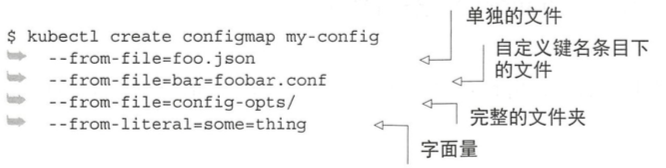
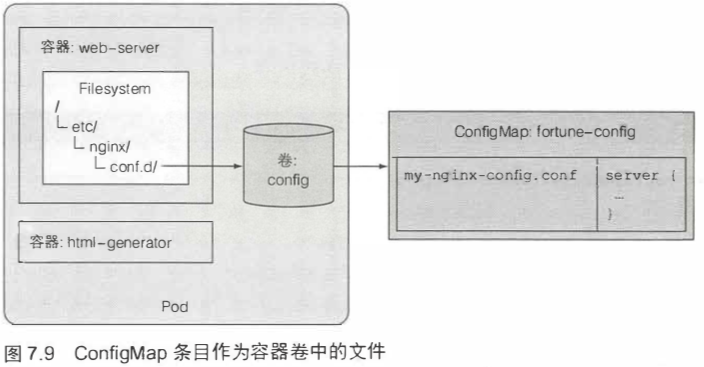
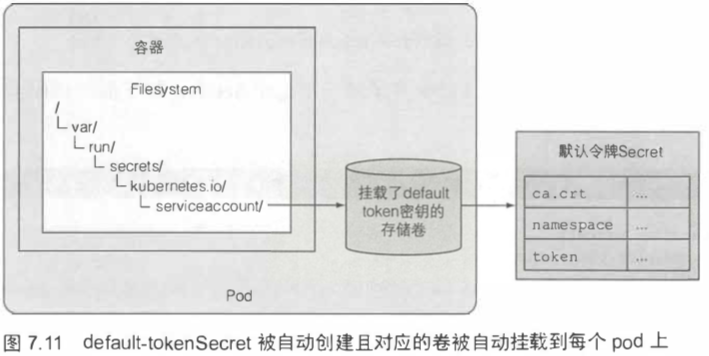
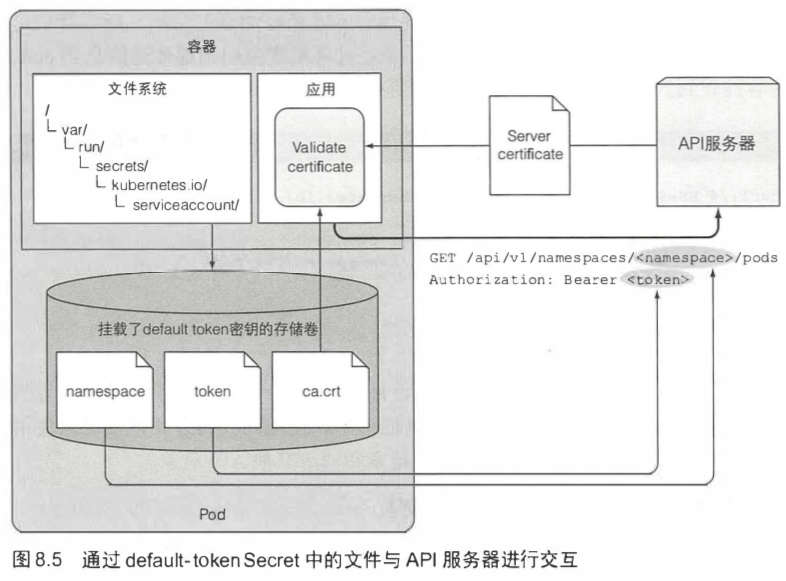
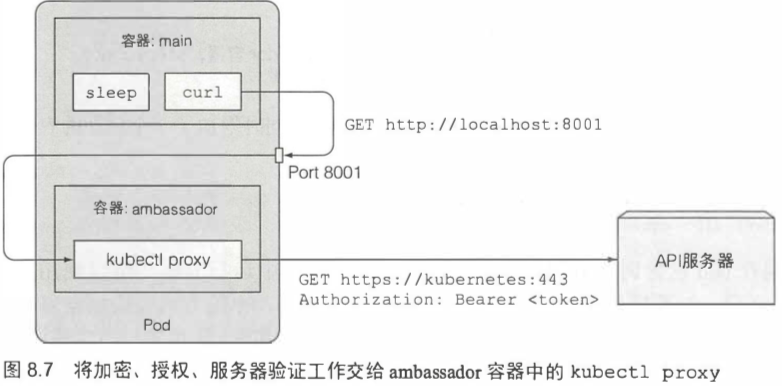
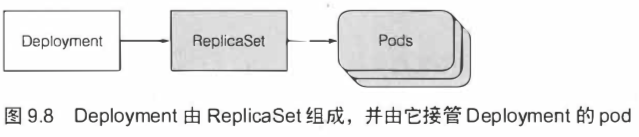
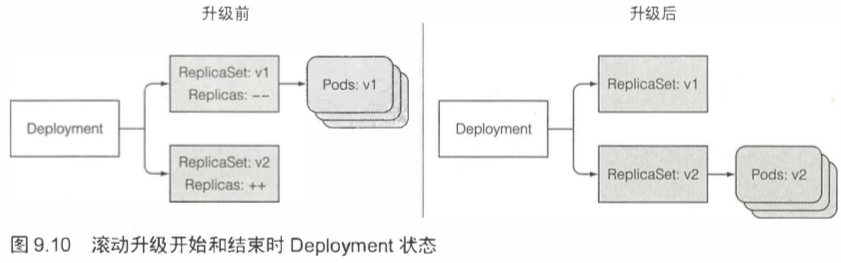
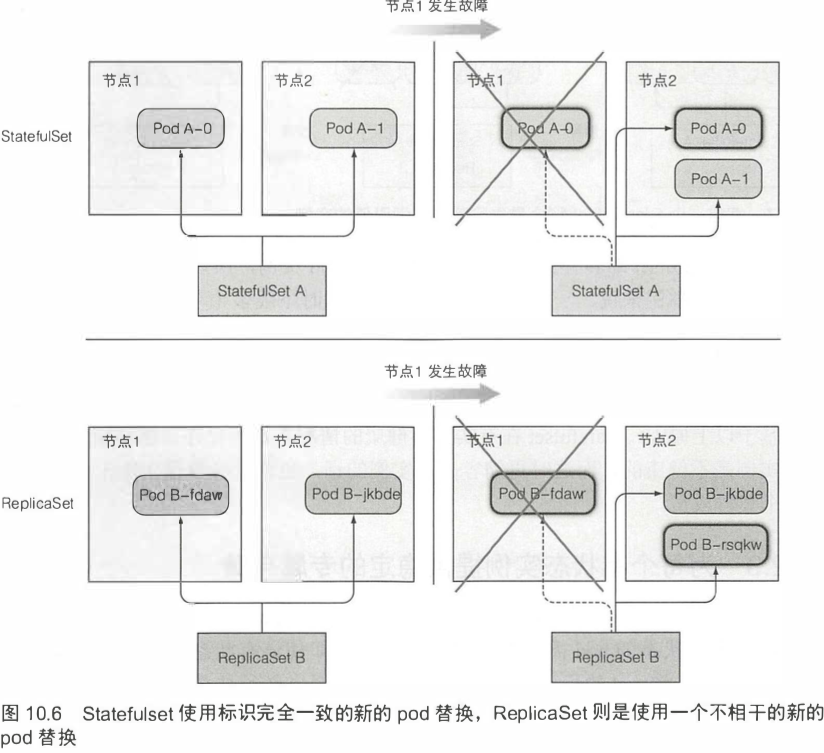
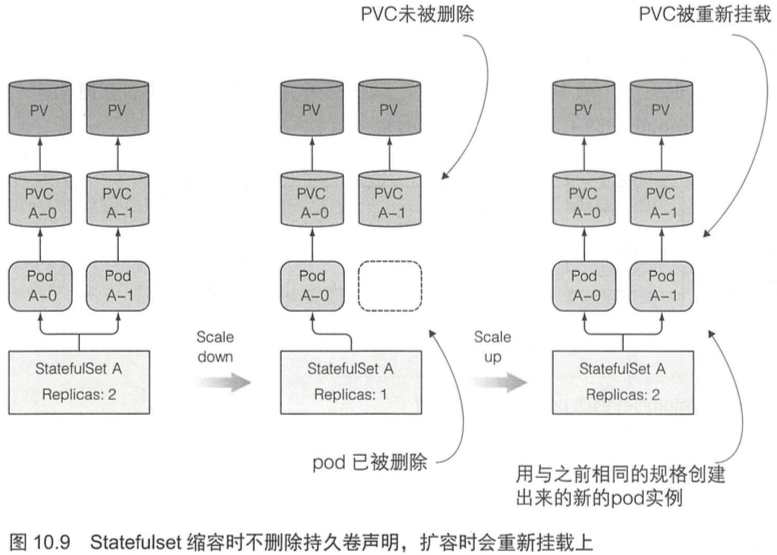
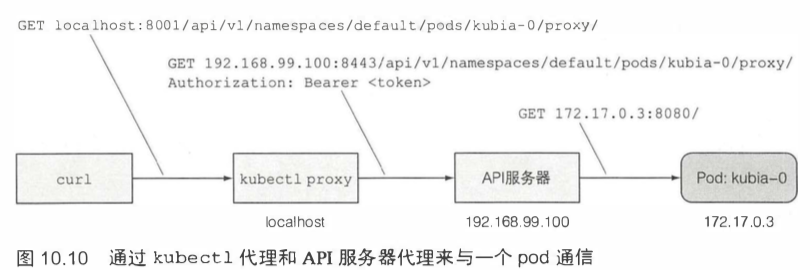
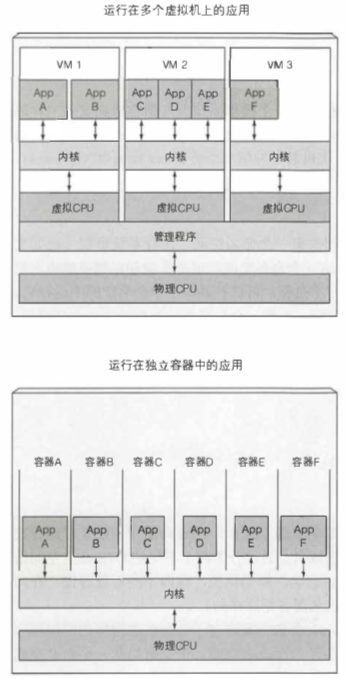
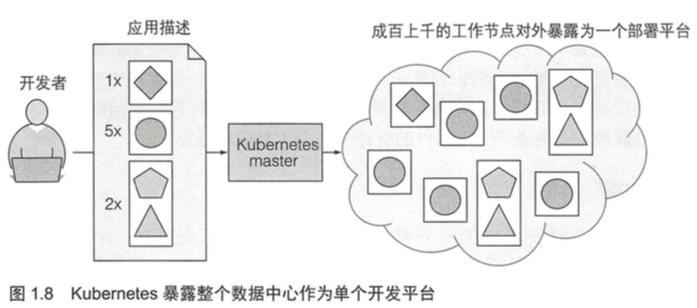
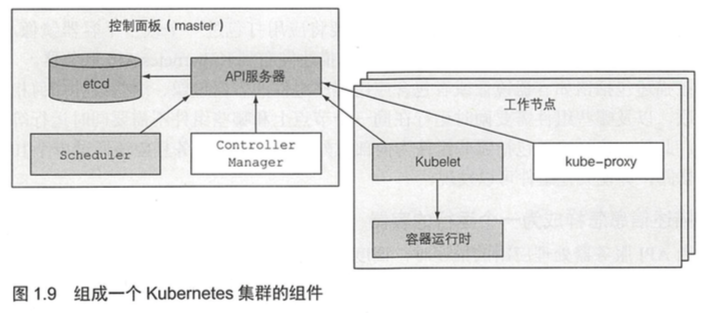
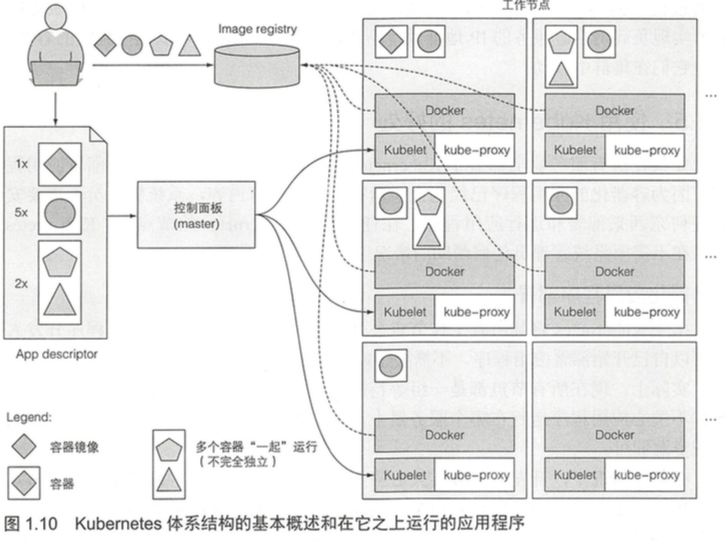
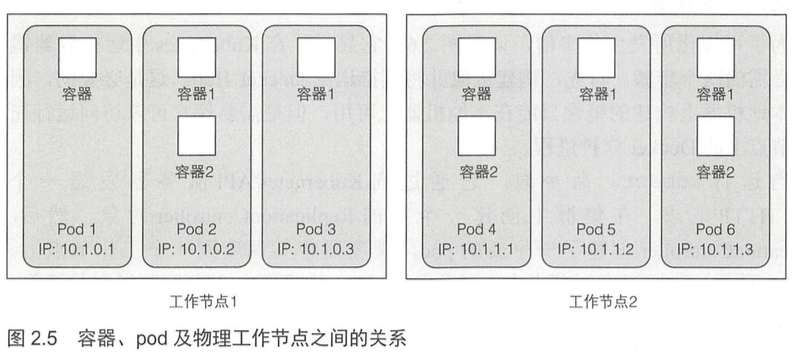
[TOC]
安利一个最近一个多月看完的YouTube Crash Course出品的《Computer Science》。
Crash Course涵盖了许多学科,包括计算机科学、天文学、哲学、文学、物理学、生物学、心理学、经济学等多个学科系列。听说其它系列也很赞,准备有时间陆续去看感兴趣的学科。

感谢Carrie Anne老师!

以下三个平台都可享用。
- B站:https://www.bilibili.com/video/av21376839/
- GitHub:https://github.com/1c7/Crash-Course-Computer-Science-Chinese
- YouTube:https://www.youtube.com/watch?v=tpIctyqH29Q&list=PLH2l6uzC4UEW0s7-KewFLBC1D0l6XRfye
从这个系列可以看到Computer Science的全景(almost)以及未来的蓝图。也很好地解释了抽象在计算机科学领域的重要性。
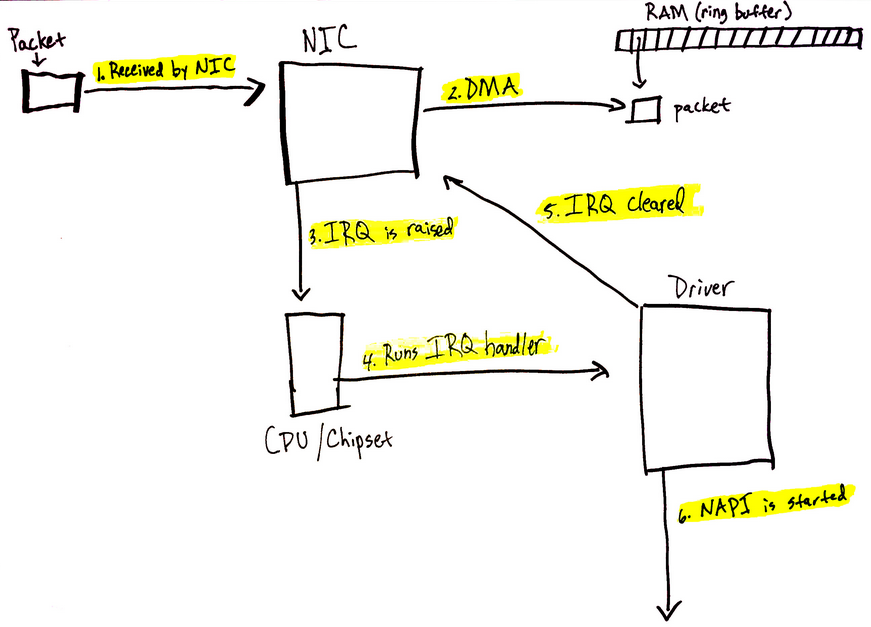
尤其前十集,收获很大,很多遗失和零碎的知识被串起来了。晶体管作为开关,依据布尔代数原理组成各种逻辑门电路,包括加法器、锁存器等,再用不同的逻辑门组成ALU/控制器/寄存器/内存等,再到指令集的设计,一层层精妙的抽象。庞大、精准、快速,真是不可思议,美妙绝伦。
正如授课者Carrie Anne小姐姐说的:
It’s hard to believe we’ve worked up from mere transistors and logic gates, all the way to computer vison, machine learning, robotics and beyond.
Hopefully you’ve developed a newfound appreciation for the incredible breadth of computing application and topic. My biggest hope is that these episodes have inspired you to learn more about how these subjects affect your life.
许倬云先生说,”我们要拿全人类曾经走过的路,都要算是我走过的路之一”。计算机科学也是如此,今天我们拥有和可以学习的知识,是站在了巨人的肩膀上。个人力量和能力微不足道,希望更多的人加入到to make the world a better place的队伍中来。
Computer science isn’t magic, but it sort of is. Those who know how to wield that tremendous power will be able to craft great things.No one really knows how this is going to shake out, but if history is any guide, it’ll probably be ok in the long run. Afterall, no one is advocating that 90% of people go back to farming and weaving textiles by hand.
虽然这个系列看似适合未接触过计算机科学的同学看,但我觉得作为一名程序员,也应该站在一个全局的角度,感受我们所学、正在或者将来从事的工作的现实意义。我们虽然走了很远,依然要记得当初为何要出发。
真希望所有的中学生都能把Crash Course系列的课程看一下,也许可以更早地明确自己的爱好,而不是随大流选择一个自己未来可能不感兴趣的专业。
最后附上令我最感动的一句话。
And when the sun is burned up and the Earth is space dust, maybe our technological children will be hard at work exploring every nook and cranny of the universe, hopefully in honor of their parents’ tradition to build knowledge, impove the state of the universe and to boldly go where no one has gone before!