[TOC]
学习Go的内存管理可以帮助我们编写更高性能的代码。

引言
在Go中由runtime来进行内存管理,通过内存分配器分配堆内存,垃圾处理器回收堆上不再使用的对象和内存空间。上一节讲了内存分配,这节讲垃圾回收。
现代编程语言中,垃圾收集有很多种算法,本文只讨论Go的垃圾收集器算法。
彻底理解Go runtime的垃圾回收是比较困难的,本文只是我个人学习过程中的总结,是站在我个人角度上进行的理解和梳理,深度不够。如果要更全面地学习Go的垃圾回收,推荐阅读本文最后列出的Reference和Go的源码。
垃圾回收
概述
虽然Go的GC(Garbage Collection)和用户goroutine可以并发执行,但是需要一段时间的STW(Stop the world)。当程序占用的内存达到一定阈值时,整个应用程序会暂停。垃圾收集器扫描已经分配的所有对象并回收不再使用的内存空间。
Go的GC的STW(Stop the world)影响程序性能是常听到的说法。因为一旦触发垃圾回收,在启动STW到停止STW的过程中,CPU不执行应用代码,全部用于执行GC代码,追求实时的应用无法接受长时间的STW。
垃圾收集器是Go的runtime改进最努力的部分,针对缩短STW时间做了很多迭代优化,目的都是为了提供程序实时性。
src/runtime/mgc.go的开头有这样一段注释。
The GC runs concurrently with mutator threads, is type accurate (aka precise), allows multiple GC thread to run in parallel. It is a concurrent mark and sweep that uses a write barrier. It is non-generational and non-compacting. Allocation is done using size segregated per P allocation areas to minimize fragmentation while eliminating locks in the common case.
Go的GC是并发标记清理、使用写屏障、非紧缩、非分代的。
并发标记和用户代码同时执行让程序处于不稳定状态。用户代码在标记过程中,可能会修改已经扫描标记过的区域,或在标记过程中分配新对象。
垃圾回收最大的问题是,究竟什么时候启动垃圾回收?过早会浪费CPU资源,影响用户程序的性能;太晚会导致内存堆积。所以垃圾回收核心需要解决的问题有两个:一是抑制堆内存增长;二是充分利用CPU资源。
标记-清除算法
早期的Go用的是标记清除(mark-sweep)算法。
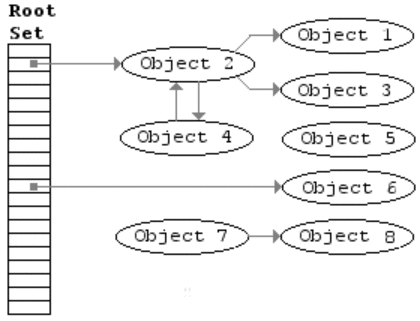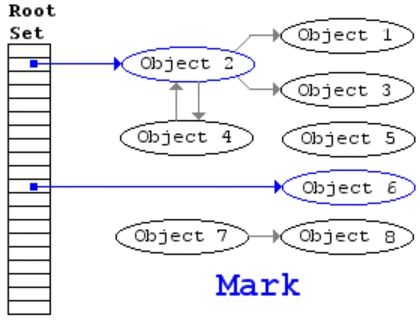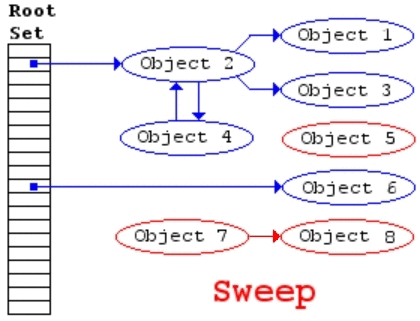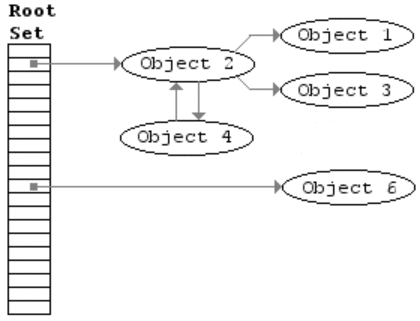
GC流程
标记清除算法分成标记和清除两个阶段。
- 标记阶段:从根对象出发,遍历并标记所有可达的对象,作上标记。
- 清除阶段:清除未被标记的对象。
缺点
- 标记需要遍历整个heap。
- 清除会产生heap碎片。
- 标记前启动STW,清除后停止STW。在该过程中,应用程序都是暂停的,程序卡顿影响性能。
三色标记算法
为了缩短标记清除算法的STW时间,用三色标记算法优化。
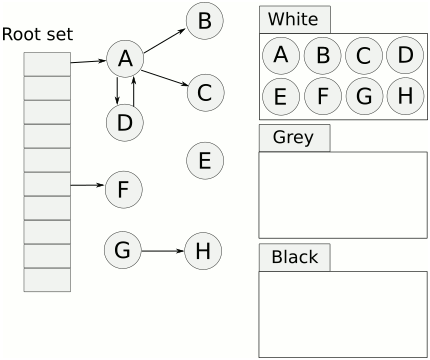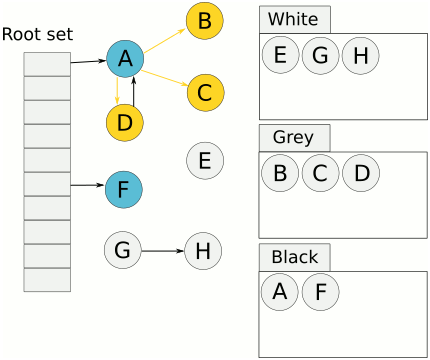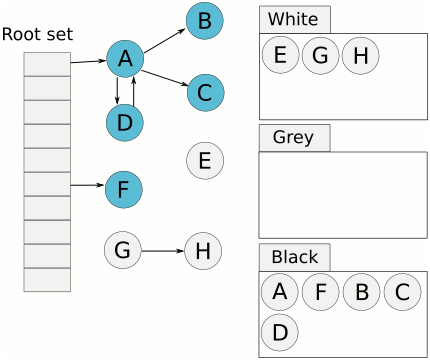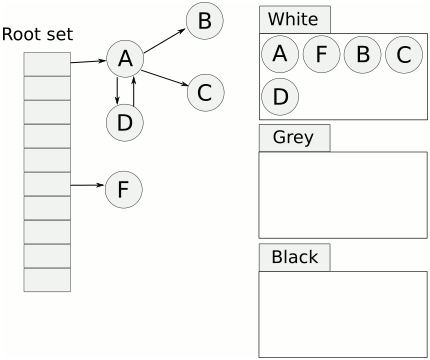
三色标记算法将程序中的对象分为黑、灰、白三类。新创建的对象,默认都是白色。当完成全部扫描和标记后,剩余的非黑即白,黑色代表活跃对象,白色代表待回收对象,清理操作只需将白色对象的内存回收即可。
GC流程
- 从根节点遍历所有对象一次,标记为灰色,放入灰色标记表。
- 遍历灰色标记表,将可达的对象,标记为灰色,放入灰色标记表。已经遍历过的灰色对象,标记为黑色,放入黑色标记表。
- 重复上一步,直到灰色标记表为空。
- 回收最后剩下的白色对象。
缺点
整个GC过程,都需要STW。
如果不使用STW,GC中途创建或删除对象引用,下面两种情况一旦同时满足,就会导致对象被错误回收,这是致命的内存管理故障。
- 如果黑色对象引用白色对象。因为黑色对象不会再被重复扫描,白色对象以及下游的对象会被GC清除。
- 如果灰色对象引用白色对象,但是引用被清除。白色对象以及下游的对象会被GC清除。
如何在保证对象不丢失情况下,减少STW时间,提高GC效率?——只要破坏其中一个条件,这个问题就被解决。
强-弱三色不变式
提出强-弱三色不变式来破坏上面两种三色标记算法不能接受的情况。
只要满足下面两种不变式的任意一种,对象就不会被错误清理。
强三色不变式
不允许黑色对象引用白色对象。—— 破坏了上述三色标记算法的缺点1。
弱三色不变式
黑色对象可以引用白色对象,但是白色对象必须被灰色对象直接或间接(多级可达)引用。—— 破坏了上述三色标记算法的缺点2。
三色标记算法+屏障机制
何为屏障?我理解是一种hook机制,在GC过程中,某些条件(并发增加/修改/删除对象)满足的时候触发回调,以满足强三色不变式或弱三色不变式,从而保证三色标记算法的正确。
有两种屏障机制,来保证三色标记算法的正确。
- 插入屏障机制:对象被引用时,触发的机制。
- 删除屏障机制:对象被删除时,触发的机制。
插入屏障机制
当A对象新增引用B对象时,将B对象标记为灰色。——满足强三色不变式。
因为栈内存操作频繁,出于性能考虑,该策略只在堆内存的对象使用。即只在堆对象触发插入屏障机制。
对于栈内存的对象,当A对象新增引用B对象时,还是将B对象标记为白色。但是在GC回收白色对象之前,重新开启STW(防止插入),扫描一次栈空间。
所以缺点是:在GC结束时需要STW来重新扫描栈。
删除屏障机制
当白色对象被删除引用时,将它标记为灰色。——满足弱三色不变式。
在栈内存和堆内存均触发删除屏障机制。
这个机制的目的是,当白色对象被删除引用时,如果有黑色对象引用白色对象,白色对象不会被错误回收。但如果白色对象真的被删除引用,在下一轮才会被清理。
所以缺点是:回收精度低。一个对象即使被真的删除了,也只能到下一轮被清理。
混合写屏障机制
为了避免重新扫描栈,进一步减少STW时间,在插入屏障机制和删除屏障机制的基础上,结合了优点,规避了缺点,引入混合写屏障机制。混合写屏障机制在GC期间通过监视内存中对象的修改,重新标色,来保障标记和用户代码并发执行。
只有堆对象触发混合写屏障机制。
具体规则是:
- GC开始时,栈上从根节点开始扫描,将全部可达对象都标记为黑色。(避免GC结束时STW重新扫描栈,因为第一轮的可达对象始终是黑色的,而那些GC操作过程中由于并发操作导致的需要被清除的对象,在下一轮GC开始时不再被标记为黑色,所以在下一轮可以被清除。)
- GC期间,创建在栈上的新对象,标记为黑色。
- GC期间,被添加的对象,标记为灰色。(满足强三色不变式)
- GC期间,被删除的对象,标记为灰色。(满足弱三色不变式)
三色标记算法+混合写屏障机制是目前Go runtime使用的垃圾回收策略。
何时触发GC
GC的触发条件有两种方式:手动触发和系统触发。
手动触发:通过应用程序调用
runtime.GC()来触发检查调用GC。系统触发:
runtime自行维护,有两个地方会定时检查和GC。
- 在分配内存时,在
mallocgc函数里,会检查调用GC。 - 后台监控线程sysmon定时会检查调用GC。
手动触发
应用程序主动调用GC函数,会阻塞当前运行的应用代码,直到GC完成。
函数位于src\runtime\malloc.go。
1 | func GC() { |
可以看到,开始执行GC的是gcStart()函数。
1 | func gcStart(trigger gcTrigger) { |
如图所示,显示了gcStart过程中状态变化,以及STW停顿的时间段,写屏障启用的时间段。
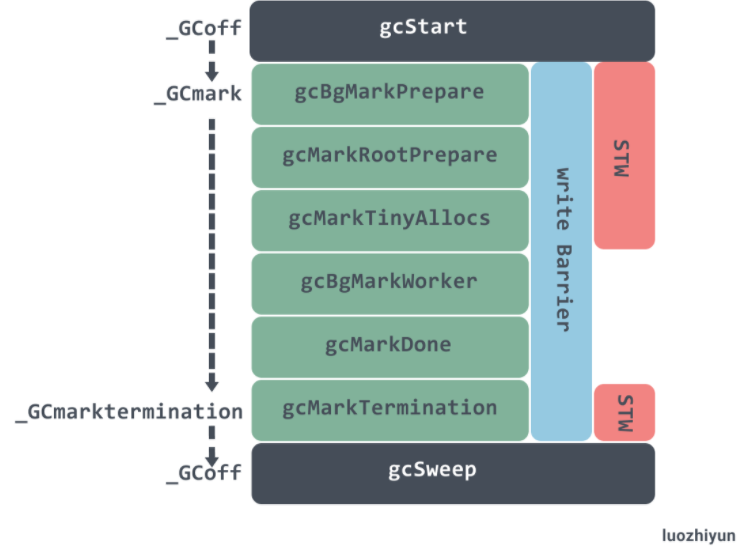
gcStart()函数有一个gcTrigger参数,这是GC的触发条件。
1 | // A gcTrigger is a predicate for starting a GC cycle. Specifically, |
gcTrigger的kind有三种,gcTriggerHeap、gcTriggerTime、gcTriggerCycle。
- gcTriggerHeap:当前分配的内存达到一定阈值时触发,这个阈值在每次GC过后都会根据堆内存的增长情况和CPU占用率来调整。
- gcTriggerTime:自从上次GC后间隔时间达到
runtime.forcegcperiod(120s,It normally doesn’t change.),将启动GC。通过sysmon监控线程调用runtime.forcegchelper检查。 - gcTriggerCycle:如果当前没有开启垃圾收集,则启动GC。
系统触发
内存分配触发
从src\runtime\malloc.go的mallocgc函数可以看到,在为对象分配堆内存后,会检查GC的触发条件,如果满足条件,则开启gcStart。
1 | func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { |
gcStart函数在上面已经分析过了。和手动调用的GC()中调用的gcStart函数是一样的。
在mallocgc中,通过调用gcTrigger.test()函数判断GC条件是否满足,满足则触发GC。上面已经提过gcTrigger的kind有三种,gcTriggerHeap、gcTriggerTime、gcTriggerCycle。只要满足其中一个kind就满足触发GC条件。
1 | func (t gcTrigger) test() bool { |
heap_live的值会在内存分配的时候进行计算。
gc_trigger的计算是通过runtime.gcSetTriggerRatio()函数。gcSetTriggerRatio函数会根据计算出来的triggerRatio来获取下次触发GC的堆大小是多少。triggerRatio是通过gcControllerState.endCycle()函数(triggerRatio每次GC后都会调整)。
监控线程sysmon触发
在runtime.main()函数中,执行init前,会启动sysmon监控线程,执行后台监控任务。
代码在src/runtime/proc.go。
1 | func main() { |
runtime在启动时,会在一个初始化函数init()里启用一个forcegchelper()函数。
1 | // start forcegc helper goroutine |
我是这么理解的,
forcegc是一个全局变量,所以forcegchelper可以由sysmon监控线程。在sysmon监控中,如果GC满足条件,会设置forcegc.idle = 0,一旦forcegc.g被唤醒,forcegchelper就会执行gcStart。
调节GC参数
Go的GC算法是固定的,用户无法去配置采用什么算法。GC相关的配置参数只有GOGC,用来表示触发GC的条件。
src\runtime\mgc.go的开头有这样一段注释。
Next GC is after we’ve allocated an extra amount of memory proportional to the amount already in use. The proportion is controlled by GOGC environment variable(100 by default). If GOGC=100 and we’re using 4M, we’ll GC again when we get to 8M(this mark is tracked in next_gc variable). This keeps the GC cost in linear proportion to the allocation cost. Adjusting GOGC just changes the linear constant (and also the amount of extra memory used).
下次GC的时机通过环境变量GOGC来控制,默认是100,即增长100%的堆内存才会触发GC。如果当前使用了4M内存,那么下次GC将会在内存达到8M的时候。设置GOGC=off将完全禁用GC。
也可以通过src/runtime/debug中的func SetGCPercent(percent int) int函数设置,设置负数将完全禁用GC。
增大GOGC,虽然可以降低GC频率,但是会增加触发GC的堆大小,可能会导致OOM,需要根据实际情况调节。
如何观察GC
可以通过不同的方法来观察GC。
GODEBUG=gctrace=1
将GODEBUG设置为gctrace=1。两种方式:
export GODEBUG=gctrace=1GODEBUG=gctrace=1 ./main
1 | gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P |
1 | $ GODEBUG=gctrace=1 ./main |
go tool trace
从标准库导入runtime/trace,并添加几行模板代码。
1 | package main |
运行程序会在trace.out文件中写入事件数据。 然后运行go tool trace trace.out,将解析跟踪文件,该命令将启动服务器,并使用跟踪数据来响应可视化操作。
内存泄露的情况
C/C++这种没有原生GC的语言,如果程序员没有及时手动释放堆内存,可能会导致内存泄露最终OOM。Go虽然有GC,但是也可能发生内存泄露。Go程序的内存泄露是因为:预期的能很快被释放的内存由于附着在了长期存活的内存上或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。举例说明三种情况。
- 情况1
1 | var cache = map[interface{}]interface{}{} |
- 情况2
1 | func keepalloc2() { |
- 情况3
1 | var ch = make(chan struct{}) |
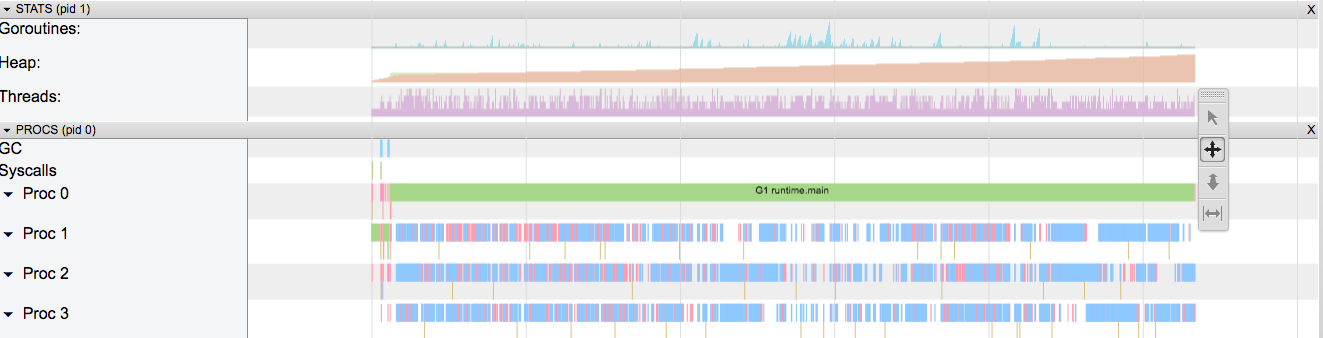
通过go tool trace验证一下。
1 | package main |
使用go tool trace trace.out命令得到下图。可以看到,运行过程中Heap持续增长,没有被回收,产生了内存泄漏。
Go的逃逸分析
Go的逃逸分析指的是编译器执行静态代码分析后,对内存管理进行的优化和简化,决定一个变量是分配到堆上还是栈上。通过逃逸分析,可以把不需要分配到堆上的变量分配到栈上,减轻分配堆内存的开销,同时也减少GC的压力,提高程序的性能。
How do I know whether a variable is allocated on the heap or the stack?
From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
从官方的回答,可以看出Go逃逸分析基本的原则是:
- 如果一个函数返回的变量被外部引用,那么它就会发生逃逸,被分配到堆上。
- 如果函数的局部变量非常大,也可能被分配到堆上。
Go的new函数分配的内存不一定在堆上。即使用new申请到的内存,如果在退出函数后没有用了,就会被分配到栈上;即使是一个普通的变量,但是逃逸分析发现在退出函数之后还有其他地方在引用,就被分配到堆上。
举个栗子。
1 | package main |
1 | $ go build -gcflags '-m -l' demo.go |
通过查看逃逸分析结果看出:
test函数里的变量a逃逸了。因为test函数返回了a的地址。- main函数里的
b也逃逸了。因为func Println(a ...interface{})参数为interface{}类型,编译期间不能确定其参数的类型,也会发生逃逸。
这个栗子只是逃逸分析里最简单的情况。
GC调优
调优思想
并非所有程序都需要关注GC,只有以下两种情况需要对GC进行性能调优。
- 对停顿敏感:用户代码需要实时性,无法接受GC长时间STW。
- 对CPU资源消耗敏感:对于频繁分配内存的应用,影响用户代码对CPU的利用率。
所以,针对这两点,除了降低GC频率(通过增大GOGC的值),GC调优的核心就是:
- 控制:优化内存的申请速度
- 减少:尽可能少申请内存,比如初始化至合适的大小,尽量使用引用传递
- 复用:复用已申请的内存
一些优化
- 对于频繁分配内存的对象,可以使用
sync.Pool进行内存复用,减少分配内存频次,从而降低GC频率。 - 控制内存分配的速度,限制goroutine的数量,从而提高赋值器对CPU的利用率。
slice和map等结构提前分配足够的内存,降低扩容时多余的拷贝。- 不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要GC标记清除,减少GC频率。
- 避免
string与[]byte转换,两者发生转换的时候,底层数据结结构会进行复制,因此导致GC效率会变低(有优化的方法)。 - 少量使用
+连接string。因为string是一个只读类型,Go不能直接修改string类似变量的内存空间,针对它的每一个操作都会创建一个新的string。如果是大量小文本拼接,用strings.Join;如果是大量大文本拼接,用bytes.Buffer。
GC优化点不只这些,等我研究一下有时间再细讲。
Reference
[1]. https://draveness.me/golang/
[2]. https://www.luozhiyun.com/archives/475
[3]. https://golang.design/under-the-hood/zh-cn/part2runtime/ch08gc/pacing/
[4]. https://www.kancloud.cn/aceld/golang/1958308
[5]. https://pkg.go.dev/runtime?utm_source=godoc
[6]. https://www.bookstack.cn/read/qcrao-Go-Questions/GC-GC.md
[7]. https://golang.org/doc/faq#stack_or_heap

